25 May 2026
Revisiting GSM-Symbolic: Do 2026 Frontier Models Still Fail at Confounded Grade School Math?
Day 8 of Inkhaven: 30 Days of Posts
TL;DR
The GSM-Symbolic paper (ICLR 2025) purported to show that language models rely on pattern matching rather than genuine reasoning by demonstrating that perturbing the questions to make them break the pattern of the original question would catastrophically reduce performance in the model. Running the results again in March 2026 with GPT4o, Claude Opus 4.6, and Claude Haiku 4.5 shows that we precisely replicate the original findings only when we do not audit out examples that may actually be ambiguous for the model. When we carefully remove samples that may genuinely impact the calculation, the effect is drastically reduced. This implies that the massive drop in performance is simply the models making a reasonable judgement to act on the "irrelevant" added data because it might be important.
Introduction
This result likely comes as little surprise, but I have seen this paper and results shared triumphantly as recently as last week as though it still applied to current models, and this made me sufficiently frustrated that I wanted to see exactly how far they've come with the hope of setting the record a little more straight. I also haven't seen any follow up work explicitly demonstrating that this is no longer the case.
Background
In October 2024, Mirzadeh et al. from Apple published "GSM-Symbolic: Understanding the Limitations of Mathematical Reasoning in Large Language Models." The paper made three claims:
-
LLMs show noticeable variance when the same question is asked with different names and values.
-
Performance declines when numerical values are altered.
-
Adding irrelevant information ("No-Op" clauses) causes catastrophic drops of up to 65%, suggesting LLMs pattern-match rather than reason.
The paper was published at ICLR 2025 and continues to be a commonly referenced and discussed paper. However, the models it evaluated (GPT-4o, Llama 3 8B, Phi-3, Gemma 2, etc.) are now around 18 months old. We wanted to test if the results still hold.
Original Paper Results (2024 Models)
For context, here are selected results from the original paper:
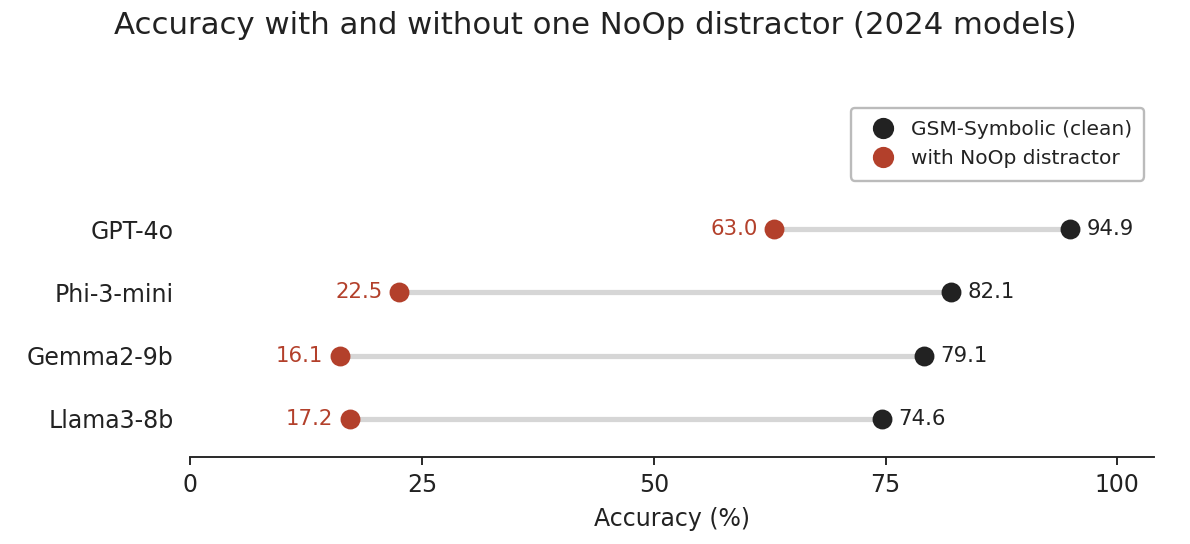 In the original paper, a single NoOp distractor collapsed accuracy on every 2024 model.
In the original paper, a single NoOp distractor collapsed accuracy on every 2024 model.
The original results were striking. Even GPT-4o, the strongest model tested, dropped from 94.9% to 63.0% when irrelevant confounders were added.
Methodology
We followed the original paper's evaluation protocol as closely as possible:
- GSM-Symbolic: We used the official dataset from Apple's repository (apple/ml-gsm-symbolic) and use only 1/5th of the 5k sample dataset due to compute constraints. We evaluate 1,000 questions (100 templates x 10 instances) per model.
- GSM-NoOp: Apple did not release the GSM-NoOp dataset. We generated our own using a three-stage pipeline:
- Generation: Claude Opus 4.6 generated a distractor clause for each of the 1,000 questions (945 usable after dropping malformed generations), each adding one irrelevant-but-plausible numerical statement to a GSM-Symbolic question. The correct answer remains unchanged. We provided all three NoOp examples from the original paper as guidance for the style of distractor.
- Audit: We audit the dataset using Opus and GPT-5.5 and label each distractor TRULY_IRRELEVANT / AMBIGUOUS / ACTUALLY_RELEVANT. Using a different model family from the generator avoids testing on cases which the generator model labeled as ambiguous.
- Filtering: Only samples GPT-5.5 classified as TRULY_IRRELEVANT were retained: 117 out of 945 (12.4%). The rest were excluded from primary evaluation because a reasonable solver might fold them into the calculation.
We found that this filtering step was genuinely challenging, with most of the samples generated by Claude Opus 4.6 needing to be filtered out even when having been specifically prompted to avoid ambiguous samples.
Examples of distractors that passed our audit:
- "The store is offering a bulk discount of 15% off for purchases of 50 or more anchors" (a conditional discount that does not apply to the quantity asked)
- "In February, Luis had taken 3 unpaid days off" (a past month; the question is about a later total)
- "4 of the boys are siblings of some of the girls" (a relationship that changes no count)
Examples of distractors that were filtered out as ambiguous:
-
"although 3 of Qasim's baskets were later reviewed and confirmed as 2-pointers instead of 3-pointers" (plausibly changes the points total)
-
"though last month they were on sale for €12 each" (given 2 prices, both might be valid)
-
"though last season the same bags used to contain 8 kgs each" (an alternate weight for the same item)
-
Prompting: 8-shot chain-of-thought with the standard GSM8K shots from the lm-evaluation-harness, matching the paper's format exactly. For many of the reasoning models the only available temperature was 1, so where possible we used 0 to match the original paper and where not possible we used 1.
-
Answer extraction: We take only the last number in the response, as per the original paper.
Results
We evaluated GPT-4o, Claude Opus 4.6, and Claude Haiku 4.5, capturing the best performer from the original paper, the current frontier model, and a small but reasonably strong reasoning model. (GPT-4o is gpt-4o-2024-08-06, the snapshot current when the paper was published.)
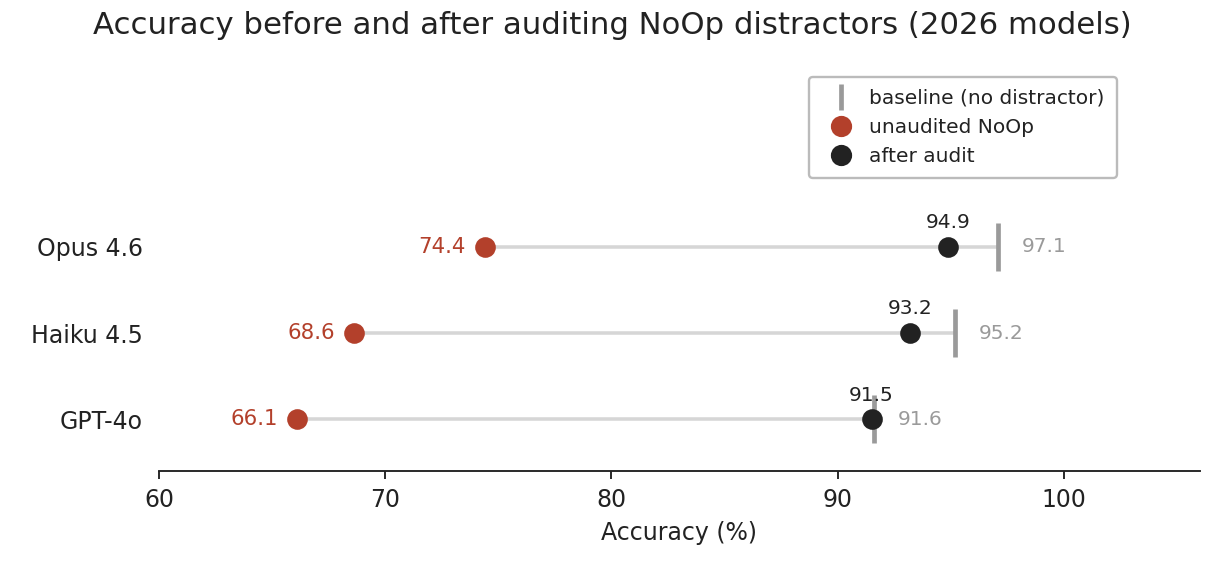 Accuracy on NoOp questions: unaudited, vs. after filtering the distractors to include only truly irrelevant samples. We compare against each model's no-distractor baseline (grey tick).
Accuracy on NoOp questions: unaudited, vs. after filtering the distractors to include only truly irrelevant samples. We compare against each model's no-distractor baseline (grey tick).
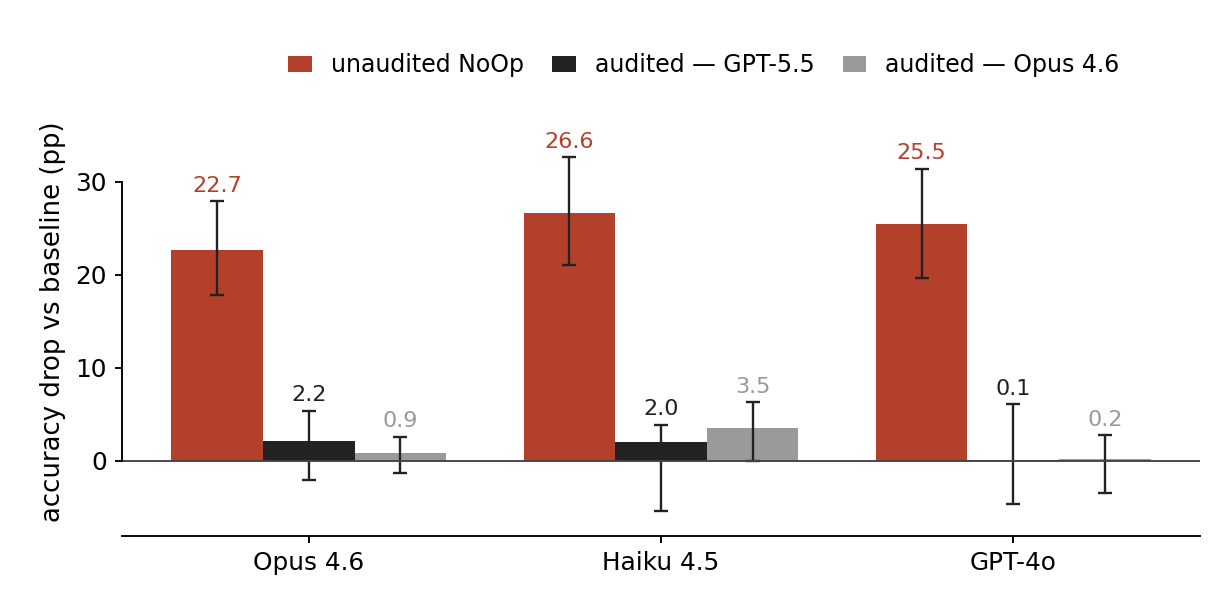 Accuracy drop vs. baseline (pp). Error bars on unaudited = template-clustered 95% CI; audited drops are indistinguishable from zero under either auditor.
Accuracy drop vs. baseline (pp). Error bars on unaudited = template-clustered 95% CI; audited drops are indistinguishable from zero under either auditor.
The two auditors disagree on borderline cases (κ = 0.32; 12% vs 36% kept), but every audited drop is statistically indistinguishable from zero.
Discussion and Caveats
Our NoOp data was LLM-generated. Apple did not release the original GSM-NoOp dataset. We generated our distractor clauses using Claude Opus 4.6 and had GPT-5.5 audit them for relevance. These may be systematically easier or different from Apple's hand-crafted distractors. We cannot make a direct apples-to-apples comparison on NoOp. However, the fact that our unfiltered dataset exhibits almost the exact same drop as the original paper is reasonable evidence that the distribution of the data was very similar to ours.
In the original paper, the authors do not mention whether the data was generated by hand, by LLM, whether any auditing was applied or quality controls were used. Because the data was not shared we cannot confirm either way.
We do observe that in our dataset that aims to measure exclusively irrelevant but potentially misleading examples only a minor decrease to the models' scores (0-2 percentage points, none statistically distinguishable from zero).
The fact that models so closely track the ambiguity classification indicates that the models are responding specifically to the content of the distractors and not simply their presence, considering they handle the non-ambiguous cases without a problem. From the model's perspective, the instruction is simply not clear, and the test doesn't tell us about their failure to reason.
We used 1,000 questions instead of the full 5,000, using 100 templates with 10 instances each. Because the 10 instances of a template are number-swapped variants of one underlying problem, we report template-clustered bootstrap intervals (resampling the 100 templates) rather than treating the 1,000 rows as independent.
This doesn't mean LLMs can "truly reason." GSM-Symbolic tests grade-school math. Saturating this benchmark tells us these models handle elementary arithmetic robustly, not that they can do advanced mathematics or formal reasoning. Harder benchmarks (FrontierMath, ARC-AGI-2, Humanity's Last Exam) exist to test true reasoning abilities in models.
Conclusion
The GSM-Symbolic paper made valid and important observations about the models available in mid-2024. Those observations no longer describe the current frontier. The original claims do not seem defensible given that a quality audit of the distractors erases the effect almost completely.
The results indicate that the model is simply making a reasonable inference that the confounders added to the NoOp dataset are real signals to adjust its calculations, because why else would the questioner mention "4 out of the 20 apricots on a given tree are unusually small". If the questioner didn't intend for them to be excluded from the calculation then why mention it?
We believe that, given the reach of this paper in shaping the discourse, the NoOp dataset should be shared to allow true independent replication of the original findings, so that the claims that models cannot reason can be checked fully. Given that some researchers still cite this work, the replication is all the more valuable.
Leave a comment
Comments are public. Email will not be displayed publicly.
Questions, thoughts?
No comments yet. Be the first to leave one below.